当前期刊数: 85
1 引言
词法、语法、语义分析概念都属于编译原理的前端领域,而这次的目的是做 具备完善语法提示的 SQL 编辑器,只需用到编译原理的前端部分。
经过连续几期的介绍,《手写 SQL 编译器》系列进入了 “智能提示” 模块,前几期从 词法到文法、语法,再到构造语法树,错误提示等等,都是为 “智能提示” 做准备。
由于智能提示需要对词法分析、语法分析做深度定制,所以我们没有使用 antlr4 等语法分析器生成工具,而是创造了一个 JS 版语法分析生成器 syntax-parser。
这次一口气讲完如何从 syntax-parser 到做一个具有智能提示功能的 SQL 编辑器。
2 精读
从语法解析、智能提示和 SQL 编辑器封装三个层次来介绍,这三个层次就像俄罗斯套娃一样具有层层递进的关系。
为了更清晰展现逻辑层次,同时满足解耦的要求,笔者先从智能提示整体设计架构讲起。
智能提示的架构
syntax-parser 是一个 JS 版的语法分析器生成器,除了类似 antlr4 基本语法分析功能外,还支持专门为智能提示优化的功能,后面会详细介绍。整体架构设计如下图所示:
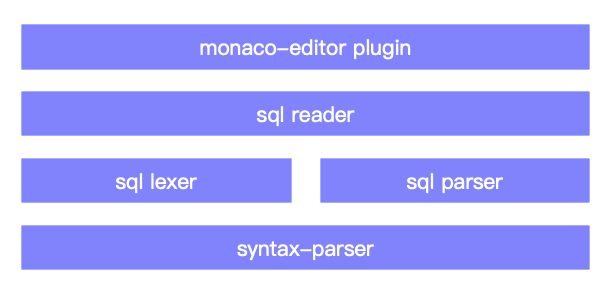
- 首先需要实现 SQL 语法,我们利用语法分析器生成器 syntax-parser,生成一个 SQL 语法分析器,这一步其实是利用 syntax-parser 能力完成了
sql lexer与sql parser。 - 为了解析语法树含义,我们需要在
sql parser基础之上编写一套sql reader,包含了一些分析函数解析语法树的语义。 - 利用 monaco-editor 生态,利用
sql reader封装 monaco-editor 插件,同时实现 用户 <=> 编辑器 间的交互,与 编辑器 <=> 语义分析器 间的交互。
语法解析器
syntax-parser 分为词法分析、语法分析两步。词法分析主要利用正则构造一个有穷自动机,大家都学过的 “编译原理” 里有更完整的解读,或者移步 精读《手写 SQL 编译器 - 词法分析》,这里主要介绍语法分析。
词法分析的输入是语法分析输出的 Tokens。Tokens 就是一个个单词,Token 结构存储了单词的值、位置、类型。
我们需要构造一个执行链条消费这些 Token,也就是可以执行文法扫描的程序。我们用四种类型节点描述文法,如下图所示:

如果不了解文法概念,可以阅读 精读《手写 SQL 编译器 - 文法介绍》
能消耗 Token 的只有 MatchNode 节点,ChainNode 节点描述先后关系(比如 expr -> name id),TreeNode 节点描述并列关系(比如 factor -> num | id),FunctionNode 是函数节点,表示还未展开的节点(如果把文法匹配比做迷宫探险,那这是个无限迷宫,无法穷尽展开)。
如何用 syntax-parser 描述一个文法,可以访问文档,现在我们已经描述了一个文法树,应该如何解析呢?
我们先找到一个非终结符作为根节点,深度遍历所有非终结符节点,遇到 MatchNode 时如果匹配,就消耗一个 Token 并继续前进,否则文法匹配失败。
遇到 ChainNode 会按照顺序执行其子节点;遇到 FunctionNode(非终结符节点)会执行这个函数,转换为一个非 FunctionNode 节点,如下图所示:
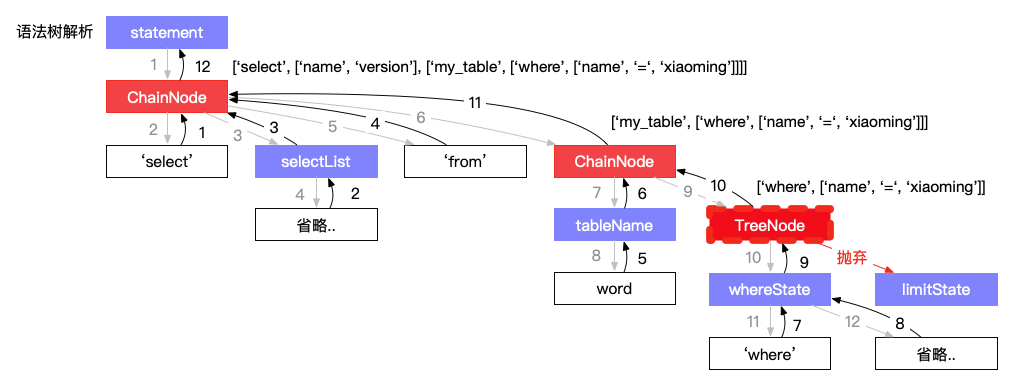
遇到 TreeNode 节点时保存这个节点运行状态并继续执行,在 MatchNode 匹配失败时可以还原到此节点继续尝试下个节点,如下图所示:

这样就具备了最基本的语法分析功能,如需更详细阅读,可以移步 精读《手写 SQL 编译器 - 语法分析》。
我们还做了一些优化,比如 First 集优化与路径缓存优化。限于篇幅,分布在以下几篇文章:
SQL 编辑器重点在于如何做输入提示,也就是如何在用户光标位置给出恰当的提示。这就是我们定制 SQL 编辑器的原因,输入提示与语法检测需要分开来做,而语法树并不能很好解决输入提示的问题。
智能提示
为了找到一个较为完美的语法提示方案,通过查阅大量资料,我决定将光标作为一个 Token 考虑来实现智能提示。
思考
我们用 | 表示光标所在位置,那么下面的 SQL 应该如何处理?
1 | |
- 从语法角度来看,它是错的,因为实际上是一个不完整语句 “select from b;”
- 从提示角度来看,它是对的,因为这是一个正确的输入过程,光标位置再输入一个单词就正确了。
你会发现,从语法和提示角度来看同一个输入,结果往往是矛盾的,所以我们需要分两条线程分别处理语法与提示。
但输入错误时,我们是无法构造语法树的,而智能提示的时机往往都是语句语法错误的时机,用过 AST 工具的人都知道。可是没有语法树,我们怎么做到智能的提示呢?试想如下语句:
1 | |
面对上面这个语句,很显然 c. 没有写完,一般的语法树解析器提示你语法错误。你可能想到这几种方案:
- 字符串匹配方式强行提示。但很显然这样提示不准确,没有完整语法树,是无法做精确解析的。而且当语法复杂时,字符串解析方案几乎无从下手。
- 把光标位置用一个特殊的字符串补上,先构造一个临时正确的语句,生成 AST 后再找到光标位置。
一般我们会采取第二种方案,看上去相对靠谱。处理过程是这样的:
1 | |
之后在 AST 中找到 $my_custom_symbol$ 字符串,对应的节点就是光标位置。实际上这可以解决大部分问题,除了关键字。
这种方案唯有关键字场景不兼容,试想一下:
1 | |
你会发现,“补全光标文字” 法,在关键字位置时,会把原本正确的语句变成错误的语句,根本解析不出语法树。
我们在 syntax-parser 解析引擎层就解决了这个问题,解决方案是 连同光标位置一起解析。
两个假设
我们做两个基本假设:
- 需要自动补全的位置分为 “关键字” 与 “非关键字”。
- “非关键字” 位置基本都是由字符串构成的。
关键字:
因此针对第一种假设,syntax-parser 内置了 “关键字提示” 功能。因为 syntax-parser 可以拿到你配置的文法,因此当给定光标位置时,可以拿到当前位置前一个 Token,通过回溯和平行尝试,将后面所有可能性提示出来,如下图:

输入是 select a |,灰色部分是已经匹配成功的部分,而我们发现光标位置前一个 Token 正是红色标识的 word,通过尝试运行推导,我们发现,桔红色标记的 ',' 和 'from' 都是 word 可能的下一个确定单词,这种单词就是 SQL 语法中的 “关键字”,syntax-parser 会自动告诉你,光标位置可能的输入是 [',', 'from']。
所以关键字的提示已经在 syntax-parser 层内置解决了!而且无论语法正确与否,都不影响提示结果,因为算法是 “寻找光标位置前一个 Token 所有可能的下一个 Token”,这可以完全由词法分析器内置支持。
非关键字:
针对非关键字,我们解决方案和用特殊字符串补充类似,但也有不同:
- 在光标位置插入一个新 Token,这个 Token 类型是特殊的 “光标类型”。
- 在 word 解析函数加一个特殊判断,如果读到 “光标类型” Token,也算成功解析,且消耗 Token。
因此 syntax-parser 总是返回两个 AST 信息:
1 | |
分别是语法树详细信息,与光标位置在语法树中的访问路径。
对于 select a | 的情况,会生成三个 Tokens:['select', 'a', 'cursor'],对于 select a| 的情况,会生成两个 Tokens:['select', 'a'],也就是光标与字符相连时,不会覆盖这个字符。
cursorPath 的生成也比 “字符串补充” 方案更健壮,syntax-parser 生成的 AST 会记录每一个 Token 的位置,最终会根据光标位置进行比对,进而找到光标对应语法树上哪个节点。
对 .| 的处理:
可能你已经想到了,.| 情况是很通用的输入场景,比如 user. 希望提示出 user 对象的成员函数,或者 SQL 语句表名存在项目空间的情况,可能 tableName 会存在 .| 的语法。
.| 状况时,语法是错误的,此时智能提示会遇到挑战。根据查阅的资料,这块也有两种常见处理手法:
- 在
.位置加上特殊标识,让语法解析器可以正确解析出语法树。 - 抹去
.,先让语法正确解析,再分析语法树拿到.前面 Token 的属性,推导出后面的属性。
然而这两种方式都不太优雅,syntax-parser 选择了第三种方式:隔空打牛。
通过抽象,我们发现,无论是 user.name 还是 udf:count() 这种语法,都要求在某个制定字符打出时(比如 . 或 :),提示到这个字符后面跟着的 Token。
此时光标焦点在 . 而非之后的字符上,那我们何不将光标偷偷移到 . 之后,进行空光标 Token 补位呢!这样不但能完全复用之前的处理思想,还可以拿到我们真正想拿到的位置:
1 | |
对比后发现,第一行拥有 4 个 Token,语法错误,而经过修改的第二行拥有 5 个 Token(一个光标补位),语法正确,且光标所在位置等价于第一行我们希望提示的位置,此问题得以解决。
SQL 编辑器封装
我们拥有了内置 “智能提示” 功能的语法解析器,定制了一套自定义的 SQL 词法、文法描述,便完成了 sql-lexer 与 sql-parser 这一层。由于 SQL 文法完善工作非常庞大,且需要持续推进,这里举流计算中,申明动态维表的例子:
1 | |
要支持这种语法,我们在非终结符 tableOption 下增加两个分支即可:
1 | |
sql-reader:
为了方便解析 SQL 语法树,我们在 sql-reader 内置了几个常用方法,比如:
- 找到距离光标位置最近的父节点。比如
select a, b, | from d会找到这个selectStatement。 - 根据表源找到所有提供的字段。表源是指
from之后跟的语法,不但要考虑嵌套场景,别名,分组,方言,还要追溯每个字段来源于哪张表(针对 join 或 union 的情况)。
有了 sql-reader,我们可以保证在这种层层嵌套 + 别名混淆 + select * 这种复杂的场景下,仍然能追溯到字段的最原始名称,最原始的表名:

这样上层业务拓展时,可以拿到足够准、足够多的信息,具有足够好的拓展型。
monaco-editor plugin:
我们也支持了更上层的封装,Monaco Editor 插件级别的,只需要填一些参数:获取表名、获取字段的回调函数就能 Work,统一了内部业务的调用方式:
1 | |
比如实现了 onInputTableField 接口,我们可以拿到当前表名信息,轻松实现字段提示:

你也许会看到,上图中鼠标位置有错误提示(红色波浪线),但依然给出了正确的推荐提示。这得益于我们对 syntax-parser 内部机制的优化,将语法检查与智能提示分为两个模块独立处理,经过语法解析,虽然抛出了语法错误,但因为有了光标的加入,最终生成了语法树。
再比如实现了 onHoverFunctionName,可以自定义鼠标 hover 在函数时的提示信息:
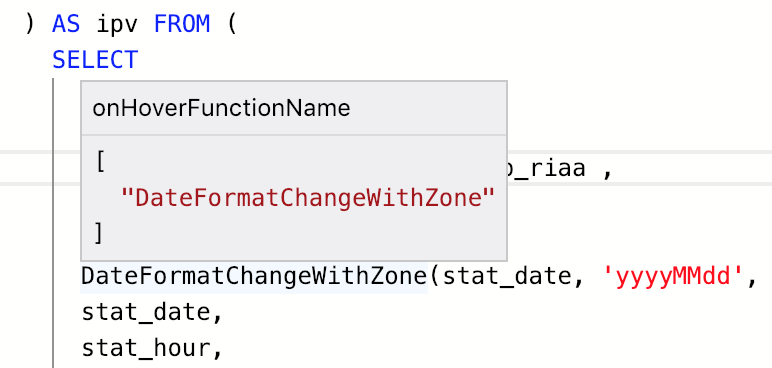
得益于 sql-reader,我们对 sql 语句做了层层解析,所以才能把自动提示做到极致。比如在做字段自动提示时,经历了如下判断步骤:

而你只需要实现 onInputTableField,告诉程序每个表可以提供哪些字段,整个流程就会严格的层层检查表名提供对原始字段与 selectList 描述的输出字段,找到映射关系并逐级传递、校验,最终 Merge 后一直冒泡到当前光标位置所在语句,形成输入建议。
4 总结
整个智能提示的封装链条如下:
syntax-parser -> sql-parser -> monaco-editor-plugin
对应关系是:
语法解析器生成器 -> SQL 语法解析器 -> 编辑器插件
这样逻辑层次清晰,解耦,而且可以从任意节点切入,进行自定义,比如:
从 syntax-parser 开始使用
从最底层开始使用,也许有两个目的:
- 上层封装的 sql-parser 不够好用,我重写一个 sql-parser’ 以及 monaco-editor-plugin’。
- 我的场景不是 SQL,而是流程图语法、或 Markdown 语法的自动提示。
针对这种情况,首先将目标文法找到,转化成 syntax-parser 的语法,比如:
1 | |
再仿照 sql-parser -> monaco-editor-plugin 的结构把上层封装依次实现。
从 sql-parser 开始使用
也许你需要的仅仅是一颗 SQL 语法树?或者你的输出目标不是 SQL 编辑器而是一个 UI 界面?那可以试试直接使用 sql-parser。
sql-parser 不仅可以生成语法树,还能找到当前光标位置所在语法树的节点,找到 SQL 某个语法返回的所有字段列表等功能,基于它,甚至可以做 UI 与 SQL 文本互转的应用。
从 monaco-editor-plugin 开始使用
也许你需要支持自动提示的 SQL 编辑器,那太棒了,直接用 monaco-editor-plugin 吧,根据你的业务场景或个人喜好,实现一个定制的 monaco-editor 交互插件。
目前我们只开源最底层的 syntax-parser,这也是业务无关的语法解析引擎生成器,期待您的使用与建议!
如果你想参与讨论,请点击这里,每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。