当前期刊数: 214
Node stream 比较难理解,也比较难用,但 “流” 是个很重要而且会越来越常见的概念(fetch 返回值就是流),所以我们有必要认真学习 stream。
好在继 node stream 之后,又推出了比较好用,好理解的 web streams API,我们结合 Web Streams Everywhere (and Fetch for Node.js)、2016 - the year of web streams、ReadableStream、WritableStream 这几篇文章学一下。
node stream 与 web stream 可以相互转换:
.fromWeb()将 web stream 转换为 node stream;.toWeb()将 node stream 转换为 web stream。
精读
stream(流)是什么?
stream 是一种抽象 API。我们可以和 promise 做一下类比,如果说 promise 是异步标准 API,则 stream 希望成为 I/O 的标准 API。
什么是 I/O?就是输入输出,即信息的读取与写入,比如看视频、加载图片、浏览网页、编码解码器等等都属于 I/O 场景,所以并不一定非要大数据量才算 I/O,比如读取一个磁盘文件算 I/O,同样读取 "hello world" 字符串也可以算 I/O。
stream 就是当下对 I/O 的标准抽象。
为了更好理解 stream 的 API 设计,以及让你理解的更深刻,我们先自己想一想一个标准 I/O API 应该如何设计?
I/O 场景应该如何抽象 API?
read()、write() 是我们第一个想到的 API,继续补充的话还有 open()、close() 等等。
这些 API 确实可以称得上 I/O 场景标准 API,而且也足够简单。但这些 API 有一个不足,就是缺乏对大数据量下读写的优化考虑。什么是大数据量的读写?比如读一个几 GB 的视频文件,在 2G 慢网络环境下访问网页,这些情况下,如果我们只有 read、write API,那么可能一个读取命令需要 2 个小时才能返回,而一个写入命令需要 3 个小时执行时间,同时对用户来说,不论是看视频还是看网页,都无法接受这么长的白屏时间。
但为什么我们看视频和看网页的时候没有等待这么久?因为看网页时,并不是等待所有资源都加载完毕才能浏览与交互的,许多资源都是在首屏渲染后再异步加载的,视频更是如此,我们不会加载完 30GB 的电影后再开始播放,而是先下载 300kb 片头后就可以开始播放了。
无论是视频还是网页,为了快速响应内容,资源都是 在操作过程中持续加载的,如果我们设计一个支持这种模式的 API,无论资源大还是小都可以覆盖,自然比 read、wirte 设计更合理。
这种持续加载资源的行为就是 stream(流)。
什么是 stream
stream 可以认为在形容资源持续流动的状态,我们需要把 I/O 场景看作一个持续的场景,就像把一条河的河水导流到另一条河。
做一个类比,我们在发送 http 请求、浏览网页、看视频时,可以看作一个南水北调的过程,把 A 河的水持续调到 B 河。
在发送 http 请求时,A 河就是后端服务器,B 河就是客户端;浏览网页时,A 河就是别人的网站,B 河就是你的手机;看视频时,A 河是网络上的视频资源(当然也可能是本地的),B 河是你的视频播放器。
所以流是一个持续的过程,而且可能有多个节点,不仅网络请求是流,资源加载到本地硬盘后,读取到内存,视频解码也是流,所以这个南水北调过程中还有许多中途蓄水池节点。
将这些事情都考虑到一起,最后形成了 web stream API。
一共有三种流,分别是:writable streams、readable streams、transform streams,它们的关系如下:
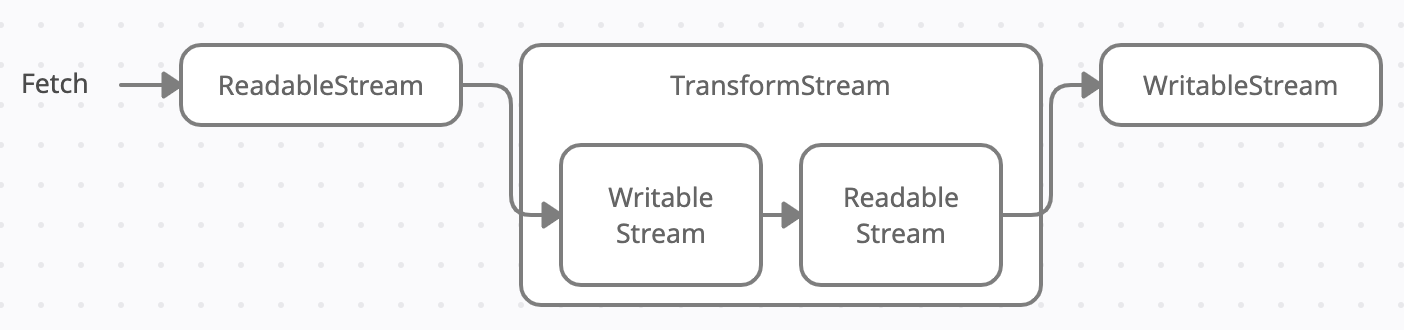
- readable streams 代表 A 河流,是数据的源头,因为是数据源头,所以只可读不可写。
- writable streams 代表 B 河流,是数据的目的地,因为要持续蓄水,所以是只可写不可读。
- transform streams 是中间对数据进行变换的节点,比如 A 与 B 河中间有一个大坝,这个大坝可以通过蓄水的方式控制水运输的速度,还可以安装滤网净化水源,所以它一头是 writable streams 输入 A 河流的水,另一头提供 readable streams 供 B 河流读取。
乍一看很复杂的概念,但映射到河水引流就非常自然了,stream 的设计非常贴近生活概念。
要理解 stream,需要思考下面三个问题:
- readable streams 从哪来?
- 是否要使用 transform streams 进行中间件加工?
- 消费的 writable streams 逻辑是什么?
还是再解释一下,为什么相比 read()、write(),stream 要多这三个思考:stream 既然将 I/O 抽象为流的概念,也就是具有持续性,那么读取的资源就必须是一个 readable 流,所以我们要构造一个 readable streams(未来可能越来越多函数返回值就是流,也就是在流的环境下工作,就不用考虑如何构造流了)。对流的读取是一个持续的过程,所以不是调用一个函数一次性读取那么简单,因此 writable streams 也有一定 API 语法。正是因为对资源进行了抽象,所以无论是读取还是消费,都被包装了一层 stream API,而普通的 read 函数读取的资源都是其本身,所以才没有这些额外思维负担。
好在 web streams API 设计都比较简单易用,而且作为一种标准规范,更加有掌握的必要,下面分别说明:
readable streams
读取流不可写,所以只有初始化时才能设置值:
1 | |
controller.enqueue() 可以填入任意值,相当于是将值加入队列,controller.close() 关闭后,就无法继续 enqueue 了,并且这里的关闭时机,会在 writable streams 的 close 回调响应。
上面只是 mock 的例子,实际场景中,读取流往往是一些调用函数返回的对象,最常见的就是 fetch 函数:
1 | |
可见,fetch 函数返回的 response.body 就是一个 readable stream。
我们可以通过以下方式直接消费读取流:
1 | |
也可以 readableStream.pipeThrough(transformStream) 到一个转换流,也可以 readableStream.pipeTo(writableStream) 到一个写入流。
不管是手动 mock 还是函数返回,我们都能猜到,读取流不一定一开始就充满数据,比如 response.body 就可能因为读的比较早而需要等待,就像接入的水管水流较慢,而源头水池的水很多一样。我们也可以手动模拟读取较慢的情况:
1 | |
上面例子中,如果我们一开始就用写入流对接,必然要等待 1s 才能得到完整的 'hello' 数据,但如果 1s 后再对接写入流,那么瞬间就能读取整个 'hello'。另外,写入流可能处理的速度也会慢,如果写入流处理每个单词的时间都是 1s,那么写入流无论何时执行,都比读取流更慢。
所以可以体会到,流的设计就是为了让整个数据处理过程最大程度的高效,无论读取流数据 ready 的多迟、开始对接写入流的时间有多晚、写入流处理的多慢,整个链路都是尽可能最高效的:
- 如果 readableStream ready 的迟,我们可以晚一点对接,让 readableStream 准备好再开始快速消费。
- 如果 writableStream 处理的慢,也只是这一处消费的慢,对接的 “水管” readableStream 可能早就 ready 了,此时换一个高效消费的 writableStream 就能提升整体效率。
writable streams
写入流不可读,可以通过如下方式创建:
1 | |
写入流不用关心读取流是什么,所以只要关心数据写入就行了,实现写入回调 write。
write 回调需要返回一个 Promise,所以如果我们消费 chunk 的速度比较慢,写入流执行速度就会变慢,我们可以理解为 A 河流引水到 B 河流,就算 A 河流的河道很宽,一下就把河水全部灌入了,但 B 河流的河道很窄,无法处理那么大的水流量,所以受限于 B 河流河道宽度,整体水流速度还是比较慢的(当然这里不可能发生洪灾)。
那么 writableStream 如何触发写入呢?可以通过 write() 函数直接写入:
1 | |
也可以通过 pipeTo() 直接对接 readableStream,就像本来是手动滴水,现在直接对接一个水管,这样我们只管处理写入就行了:
1 | |
当然通过最原始的 API 也可以拼装出 pipeTo 的效果,为了理解的更深刻,我们用原始方法模拟一个 pipeTo:
1 | |
transform streams
转换流内部是一个写入流 + 读取流,创建转换流的方式如下:
1 | |
chunk 是 writableStream 拿到的包,controller.enqueue 是 readableStream 的入列方法,所以它其实底层实现就是两个流的叠加,API 上简化为 transform 了,可以一边写入读到的数据,一边转化为读取流,供后面的写入流消费。
当然有很多原生的转换流可以用,比如 TextDecoderStream:
1 | |
readable to writable streams
下面是一个包含了编码转码的完整例子:
1 | |
首先 readableStream 利用 TextEncoder 以极快的速度瞬间将 hello 这 5 个字母加入队列,并执行 controller.close(),意味着这个 readableStream 瞬间就完成了初始化,并且后面无法修改,只能读取了。
我们在 writableStream 的 write 方法中,利用 TextDecoder 对 chunk 进行解码,一次解码一个字母,并打印到控制台,然后过了 1s 才 resolve,所以写入流会每隔 1s 打印一个字母:
1 | |
这个例子转码解码处理的还不够优雅,我们不需要将转码与解码写在流函数里,而是写在转换流中,比如:
1 | |
这样 readableStream 与 writableStream 都不需要处理编码与解码,但流在中间被转化为了 Uint8Array,方便被其它转换流处理,最后经过解码转换流转换为文字后,再 pipeTo 给写入流,这样写入流拿到的就是文字了。
但也并不总是这样,比如我们要传输一个视频流,可能 readableStream 原始值就已经是 Uint8Array,所以具体要不要对接转换流看情况。
总结
streams 是对 I/O 抽象的标准处理 API,其支持持续小片段数据处理的特性并不是偶然,而是对 I/O 场景进行抽象后的必然。
我们通过水流的例子类比了 streams 的概念,当 I/O 发生时,源头的流转换是有固定速度的 x M/s,目标客户端比如视频的转换也是有固定速度的 y M/s,网络请求也有速度并且是个持续的过程,所以 fetch 天然也是一个流,速度时 z M/s,我们最终看到视频的速度就是 min(x, y, z),当然如果服务器提前将 readableStream 提供好,那么 x 的速度就可以忽略,此时看到视频的速度是 min(y, z)。
不仅视频如此,打开文件、打开网页等等都是如此,浏览器处理 html 也是一个流的过程:
1 | |
如果这个 readableStream 的 controller.enqueue 过程被刻意处理的比较慢,网页甚至可以一个字一个字的逐步呈现:Serving a string, slowly Demo。
尽管流的场景如此普遍,但也没有必要将所有代码都改成流式处理,因为代码在内存中执行速度很快,变量的赋值是没必要使用流处理的,但如果这个变量的值来自于一个打开的文件,或者网络请求,那么使用流进行处理是最高效的。
如果你想参与讨论,请 点击这里,每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。
关注 前端精读微信公众号

版权声明:自由转载-非商用-非衍生-保持署名(创意共享 3.0 许可证)