当前期刊数: 277
ChatPDF 最近比较火,上传 PDF 文件后,即可通过问答的方式让他帮你总结内容,比如让它帮你概括核心观点、询问问题,或者做观点判断。
背后用到了几个比较时髦的技术,还好有 ChatGPT for YOUR OWN PDF files with LangChain 解释了背后的原理,我觉得非常精彩,因此记录下来并做一些思考,希望可以帮到大家。
技术思路概括
由于 GPT 非常强大,只要你把 PDF 文章内容发给他,他就可以解答你对于该文章的任何问题了。– 全文完。
等等,那么为什么要提到 langChain 与 vector dataBase?因为 PDF 文章内容太长了,直接传给 GPT 很容易超出 Token 限制,就算他允许无限制的 Token 传输,可能一个问题可能需要花费 10~100 美元,这个 成本 也是不可接受的。
因此黑魔法来了,下图截取自视频 ChatGPT for YOUR OWN PDF files with LangChain:
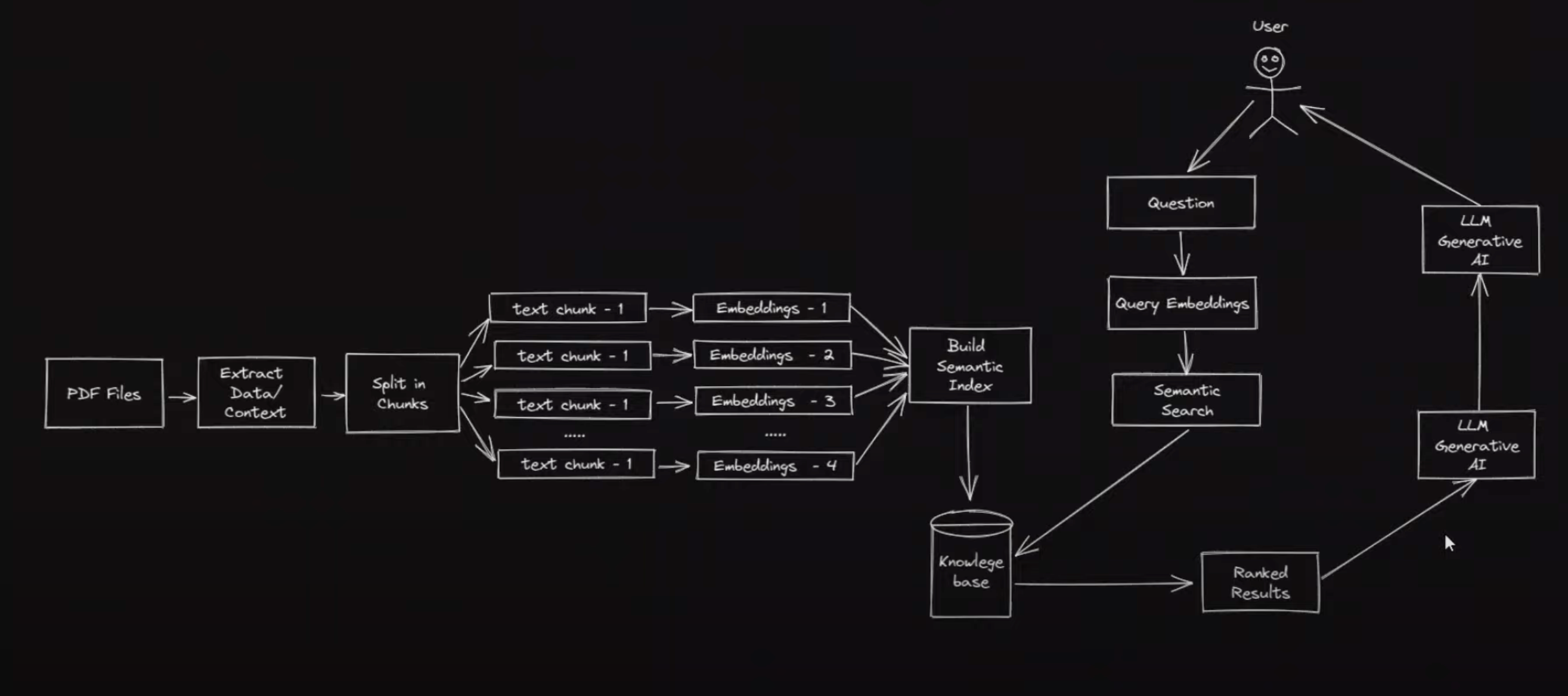
我们一步步解读:
- 找一些库把 PDF 内容文本提取出来。
- 把这些文本拆分成 N 份更小的文本,用 openai 进行文本向量化。
- 当用户提问时,对用户提问进行向量化,并用数学函数计算与 PDF 已向量化内容的相似程度。
- 把最相似的文本发送给 openai,让他总结并回答你的问题。
利用 GPT 解读 PDF 的实现步骤
我把视频里每一步操作重新介绍一遍,并补上自己的理解。
登录 colab
你可以在本地电脑运行 python 一步步执行,也可以直接登录 colab 这个 python 运行平台,它提供了很方便的 python 环境,并且可以一步步执行代码并保存,非常适合做研究。
只要你有谷歌账号就可以使用 colab。
安装依赖
要运行一堆 gpt 相关函数,需要安装一些包,虽然本质上都是不断给 gpt openapi 发 http 请求,但封装后确实会语义化很多:
1 | |
其中 tiktoken 包是教程里没有的,我执行某处代码时被提示缺少这个包,大家可以提前按上。接下来提前引入一些后面需要用到的函数:
1 | |
定义 openapi token
为了调用 openapi 服务,需要先申请 token,当你申请到 token 后,通过如下方式定义:
1 | |
默认 langchain 与 openai 都会访问 python 环境的 os.environ 来寻找 token,所以这里定义后,接下来就可以直接调用服务了。
如果你还没有 GPT openapi 的账号,详见 保姆级注册教程。(可惜的是中国被墙了,为了学习第一手新鲜知识,你需要自己找 vpn,甚至花钱买国外手机号验证码接收服务,虽然过程比较坎坷,但亲测可行)。
读取 PDF 内容
为了方便在 colab 平台读取 PDF,你可以先把 PDF 上传到自己的 Google Drive,它是谷歌推出的个人云服务,集成了包括 colab 与文件存储等所有云服务(PS:微软类似的服务叫 One Drive,好吧,理论上你用哪个巨头的服务都行)。
传上去之后,在 colab 运行如下代码,会弹开一个授权网页,授权后就可以访问你的 drive 路径下资源了:
1 | |
我们读取了 2023_GPT4All_Technical_Report.pdf 报告,这是一个号称本地可跑对标 GPT4 的服务(测评)。
将 PDF 内容文本化并拆分为多个小 chunk
首先执行如下代码读取 PDF 文本内容:
1 | |
接下来要为调用 openapi 服务对文本向量化做准备,因为一次调用的 token 数量有限制,因此我们需要将一大段文本拆分为若干小文本:
1 | |
其中 chunk_size=1000 表示一个 chunk 有 1000 个字符,而 chunk_overlap 表示下一个 chunk 会重复上一个 chunk 最后 200 字符的内容,方便给每个 chunk 做衔接,这样可以让找相似性的时候尽量多找几个 chunk,找到更多的上下文。
向量化来了!
最重要的一步,利用 openapi 对之前拆分好的文本 chunk 做向量化:
1 | |
就是这么简单,docsearch 是一个封装对象,在这一步已经循环调用了若干次 openapi 接口将文本转化为非常长的向量。
文本向量化又是一个深水区,可以看下这个 介绍视频,简单来说就是一把文本转化为一系列数字,表示 N 维的向量,利用数学计算相似度,可以把文字处理转化为连续的数字进行数学处理,甚至进行文字加减法(比如 北京-中国+美国=华盛顿)。
总之这一步之后,我们本地就拿到了各段文本与其向量的对应关系,比如 “这是一段文字” 对应的向量为 [-0.231, 0.423, -0.2347831, ...]。
利用 chain 生成问答服务
接下来要串起完整流程了,初始化一个 QA chain 表示与 GPT 使用 chat 模型进行问答:
1 | |
接下来就可以问他 PDF 相关问题了:
1 | |
当然也可以用中文提问,openapi 会调用内置模块翻译给你:
1 | |
QA 环节发生了什么?
根据我的理解,当你问出 who are the main author of the article? 这个问题时,发生了如下几步。
第一步:调用 openapi 将问题进行向量化,得到一堆向量。
第二步:利用数学函数与本地向量数据库进行匹配,找到匹配度最高的几个文本 chunk(之前我们拆分的 PDF 文本内容)。
第三步:把这些相关度最高的文本发送给 openapi,让他帮我们归纳。
对于第三步是否结合了 langchain 进行多步骤对答还不得而知,下次我准备抓包看一下这个程序与 openapi 的通信内容,才能解开其中的秘密。
当然,如果问题需要结合 PDF 所有内容才能概括出来,这种向量匹配的方式就不太行了,因为他总是发送与问题最相关的文本片段。但是呢,因为第三步的秘密还没有解决,很有可能当内容片段不够时,gpt4 会询问寻找更多相似片段,这样不断重复知道 gpt4 觉得可以回答了,再给出答案(想想觉得后背一凉)。
总结
解读 PDF 的技术思路还可以用在任意问题上,比如网页搜索:
网页搜索就是一个典型的从知识海洋里搜索关键信息并解读的场景,只要背后将所有网页信息向量化,存储在某个向量数据库,就可以做一个 GPT 搜索引擎了,步骤是:一、将用户输入关键字分词并向量化。二:在数据库进行向量匹配,把匹配度最高的几个网页内容提取出来。三:把这些内容喂给 GPT,让他总结里面的知识并回答用户问题。
向量化可以解决任意场景模糊化匹配,比如我自己的备忘录会存储许多平台账号与密码,但有一天搜索 ChatGPT 密码却没搜到,后来发现关键词写成了 OpenAPI。向量化就可以解决这个问题,他可以将无法匹配的关键词也在备忘录里搜索到。
配合向量化搜索,再加上 GPT 的思考与总结能力,一个超级 AI 助手可做的事将会远远超过我们的想象。
留给大家一个思考题:结合向量化与 GPT 这两个能力,你还能想到哪些使用场景?
如果你想参与讨论,请 点击这里,每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。
关注 前端精读微信公众号

版权声明:自由转载-非商用-非衍生-保持署名(创意共享 3.0 许可证)