当前期刊数: 239
每个 JS 执行引擎都有自己的实现,我们这次关注 V8 引擎是如何实现数组的。
本周主要精读的文章是 How JavaScript Array Works Internally?,比较简略的介绍了 V8 引擎的数组实现机制,笔者也会参考部分其他文章与源码结合进行讲解。
概述
JS 数组的内部类型有很多模式,如:
- PACKED_SMI_ELEMENTS
- PACKED_DOUBLE_ELEMENTS
- PACKED_ELEMENTS
- HOLEY_SMI_ELEMENTS
- HOLEY_DOUBLE_ELEMENTS
- HOLEY_ELEMENTS
PACKED 翻译为打包,实际意思是 “连续有值的数组”;HOLEY 翻译为孔洞,表示这个数组有很多孔洞一样的无效项,实际意思是 “中间有孔洞的数组”,这两个名词是互斥的。
SMI 表示数据类型为 32 位整型,DOUBLE 表示浮点类型,而什么类型都不写,表示数组的类型还杂糅了字符串、函数等,这个位置上的描述也是互斥的。
所以可以这么去看数组的内部类型:[PACKED, HOLEY]_[SMI, DOUBLE, '']_ELEMENTS。
最高效的类型 PACKED_SMI_ELEMENTS
一个最简单的空数组类型默认为 PACKED_SMI_ELEMENTS:
1 | |
PACKED_SMI_ELEMENTS 类型是性能最好的模式,存储的类型默认是连续的整型。当我们插入整型时,V8 会给数组自动扩容,此时类型还是 PACKED_SMI_ELEMENTS:
1 | |
或者直接创建有内容的数组,也是这个类型:
1 | |
自动降级
当我们对数组使用骚操作时,V8 会默默的进行类型降级。比如突然访问到第 100 项:
1 | |
如果突然插入一个浮点类型,会降级到 DOUBLE:
1 | |
当然如果两个骚操作一结合,HOLEY_DOUBLE_ELEMENTS 就成功被你造出来了:
1 | |
再狠一点,插入个字符串或者函数,那就到了最最兜底类型,HOLEY_ELEMENTS:
1 | |
从是否有 Empty 情况来看,PACKED > HOLEY 的性能,Benchmark 测试结果大概快 23%。
从类型来看,SMI > DOUBLE > 空类型。原因是类型决定了数组每项的长度,DOUBLE 类型是指每一项可能为 SMI 也可能为 DOUBLE,而空类型的每一项类型完全不可确认,在长度确认上会花费额外开销。
因此,HOLEY_ELEMENTS 是性能最差的兜底类型。
降级的不可逆性
文中提到一个重点,表示降级是不可逆的,具体可以看下图:
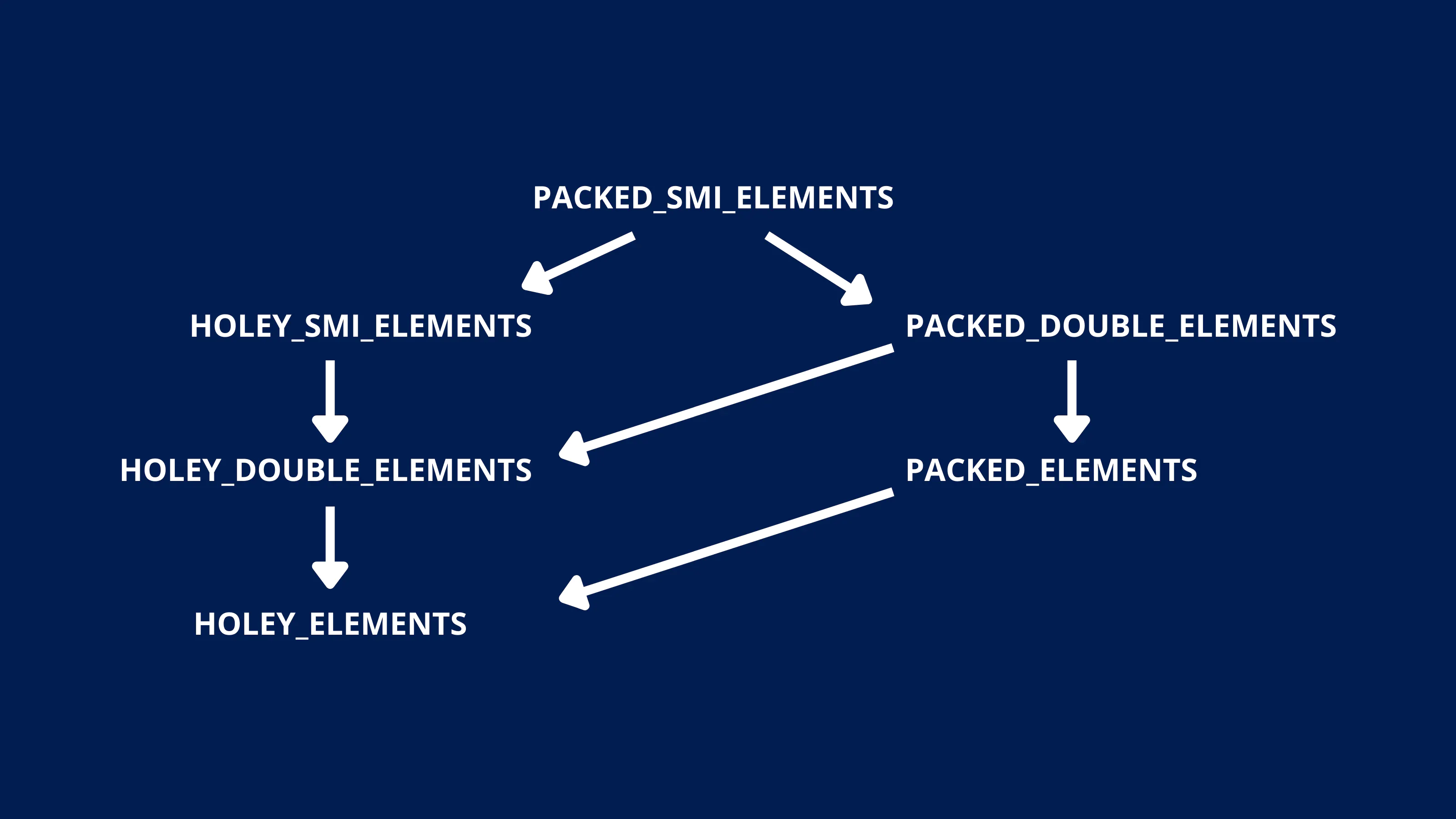
其实要表达的规律很简单,即 PACKED 只会变成更糟的 HOLEY,SMI 只会往更糟的 DOUBLE 和空类型变,且这两种变化都不可逆。
精读
为了验证文章的猜想,笔者使用 v8-debug 调试了一番。
使用 v8-debug 调试
先介绍一下 v8-debug,它是一个 v8 引擎调试工具,首先执行下面的命令行安装 jsvu:
1 | |
然后执行 jsvu,根据引导选择自己的系统类型,第二步选择要安装的 js 引擎,选择 v8 和 v8-debug:
1 | |
然后随便创建一个 js 文件,比如 test.js,再通过 ~/.jsvu/v8-debug ./test.js 就可以执行调试了。默认是不输出任何调试内容的,我们根据需求添加参数来输出要调试的信息,比如:
1 | |
这样就会把 test.js 文件的语法树打印出来。
使用 v8-debug 调试数组的内部实现
为了观察数组的内部实现,使用 console.log(arr) 显然不行,我们需要用 %DebugPrint(arr) 以 debug 模式打印数组,而这个 %DebugPrint 函数式 V8 提供的 Native API,在普通 js 脚本是不识别的,因此我们要在执行时添加参数 --allow-natives-syntax:
1 | |
同时,在 test.js 里使用 %DebugPrint 打印我们要调试的数组,如:
1 | |
输出结果为:
1 | |
也就是说,arr = [] 创建的数组的内部类型为 PACKED_SMI_ELEMENTS,符合预期。
验证不可逆转换
不看源码的话,姑且相信原文说的类型转换不可逆,那么我们做一个测试:
1 | |
打印核心结果为:
1 | |
可以看到,即便 pop 后将原数组回退到完全整型的情况,DOUBLE 也不会优化为 SMI。
再看下长度的测试:
1 | |
打印核心结果为:
1 | |
也证明了 PACKED 到 HOLEY 的不可逆。
字典模式
数组还有一种内部实现是 Dictionary Elements,它用 HashTable 作为底层结构模拟数组的操作。
这种模式用于数组长度非常大的时候,不需要连续开辟内存空间,而是用一个个零散的内存空间通过一个 HashTable 寻址来处理数据的存储,这种模式在数据量大时节省了存储空间,但带来了额外的查询开销。
当对数组的赋值远大于当前数组大小时,V8 会考虑将数组转化为 Dictionary Elements 存储以节省存储空间。
做一个测试:
1 | |
主要输出结果为:
1 | |
可以看到,占用了太多空间会导致数组的内部实现切换为 DICTIONARY_ELEMENTS 模式。
实际上这两种模式是根据固定规则相互转化的,具体查了下 V8 源码:
字典模式在 V8 代码里叫 SlowElements,反之则叫 FastElements,所以要看转化规则,主要就看两个函数:ShouldConvertToSlowElements 和 ShouldConvertToFastElements。
下面是 ShouldConvertToSlowElements 代码,即什么时候转化为字典模式:
1 | |
ShouldConvertToSlowElements 函数被重载了两次,所以有两个判断逻辑。第一处 new_capacity > size_threshold 则变成字典模式,new_capacity 表示新尺寸,而 size_threshold 是根据 3 * 已有尺寸 * 2 计算出来的。
第二处 index - capacity >= JSObject::kMaxGap 时变成字典模式,其中 kMaxGap 是常量 1024,也就是新加入的 HOLEY(孔洞) 大于 1024,则转化为字典模式。
而由字典模式转化为普通模式的函数是 ShouldConvertToFastElements:
1 | |
重点是最后一行 return 2 * dictionary_size >= *new_capacity 表示字典模式仅节省了 50% 空间时,不如切换为普通模式(fast mode)。
具体就不测试了,感兴趣同学可以用上面介绍的方法使用 v8-debug 测试一下。
总结
JS 数组使用方法非常灵活,但 V8 使用 C++ 实现时,必须转化为更底层的类型,所以为了兼顾性能,就做了快慢模式,而快模式又分了 SMI、DOUBLE;PACKED、HOLEY 模式分别处理来尽可能提升速度。
也就是说,我们在随意创建数组的时候,V8 会分析数组的元素构成与长度变化,自动分发到各种不同的子模式处理,以最大化提升性能。
这种模式使 JS 开发者获得了更好的开发者体验,而实际上执行性能也和 C++ 原生优化相差无几,所以从这个角度来看,JS 是一种更高封装层次的语言,极大降低了开发者学习门槛。
当然 JS 还提供了一些相对原生的语法比如 ArrayBuffer,或者 WASM 让开发者直接操作更底层的特性,这可以使性能控制更精确,但带来了更大的学习和维护成本,需要开发者根据实际情况权衡。
如果你想参与讨论,请 点击这里,每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。
关注 前端精读微信公众号

版权声明:自由转载-非商用-非衍生-保持署名(创意共享 3.0 许可证)