当前期刊数: 197
逻辑编排是用可视化方式描述逻辑,在一般搭建场景中用于代替逻辑描述部分。
更进一步的逻辑编排是前后端逻辑混排,一般出现在一站式 paas 平台,今天就介绍一个全面实现了逻辑编排的 paas 工具 node-red,本周精读的内容是其介绍视频:How To Create Your First Flow In Node-RED,介绍了如果利用纯逻辑编排实现一个天气查询应用,以及部署与应用迁移。
概述
想要在本地运行 Node-RED 很简单,只要下面两条命令:
1 | |
之后你就可以看到这个逻辑编排界面了:
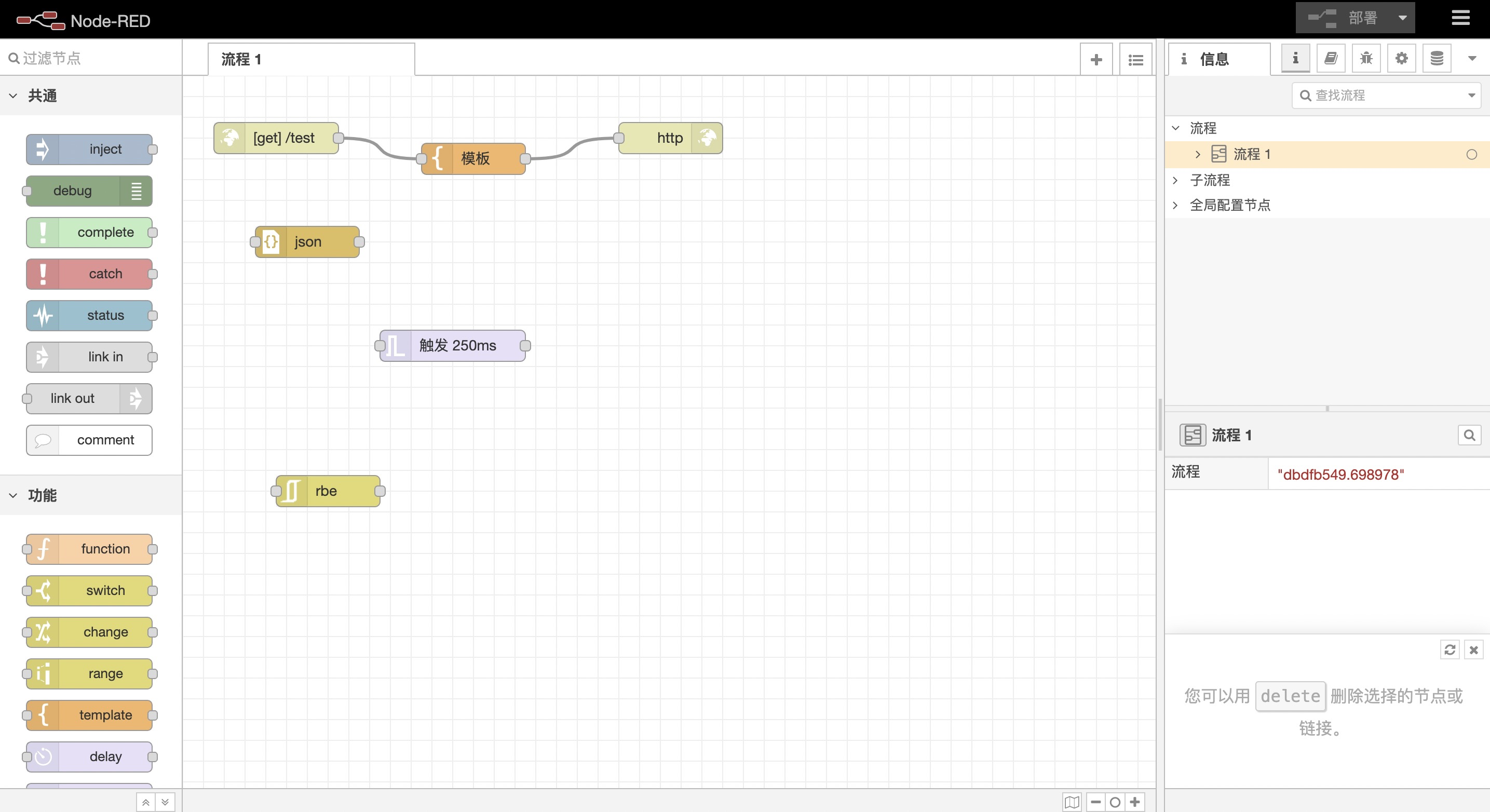
我们可以利用这些逻辑节点构建前端网站、后端服务,以及大部分开发工作。光这么说还比较抽象,我们接下来会详细介绍每个逻辑节点的作用,让你了解这些逻辑节点是如何规划设计的,以及逻辑编排到底是怎么控制研发规范来提高研发效率的。
Node-RED 截止目前共有 42 个逻辑节点,按照通用、功能、网络、序列、解析、存储分为六大类。
所有节点都可能有左右连接点,左连接点是输入,右连接点是输出,特殊节点可能有多个输入或多个输出,其实对应代码也不难理解,就是入参和出参。
下面依次介绍每个节点的功能。
通用
通用节点处理通用逻辑,比如手动输入数据、调试、错误捕获、注释等。
inject

手动输入节点。可以定期产生一些输入,由下一个节点消费。
举个例子,比如可以定期产生一些固定值,如这样一个这个对象:
1 | |
当然这里是用 UI 表单配置的:
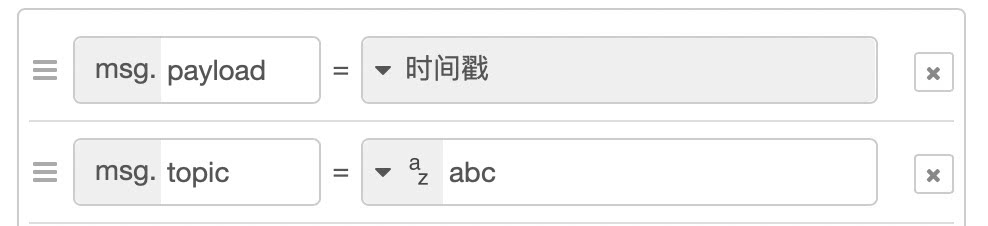
之后就是消费,几乎后面任何节点都可以消费,比如利用 change 节点来设置一些环境变量时,或者利用 template 节点设置 html 模版时,都可以拿到这里输入的变量。如果在模版里,变量通过 {{msg.payload}} 访问,如果是其它表单,甚至可以通过下拉框直接枚举选择。
然而这个节点往往用来设置静态变量,更多的输入情况是来自其它程序或者用户的,比如 http in,这个后面会讲到。其实通过这种组合关系,我们可以把任意节点的输入从生产节点替换为 inject 节点,从而实现一些 mock 效果,而 inject 节点也支持配置定时自动触发:

debug
用来调试的,当任何输出节点连接到 debug 的输入后,将会在控制台打印出输出信息,方便调试。
比如我们将 inject 的输入连上 debug 的输入,就可以在触发数据后在控制台看到打印结果:
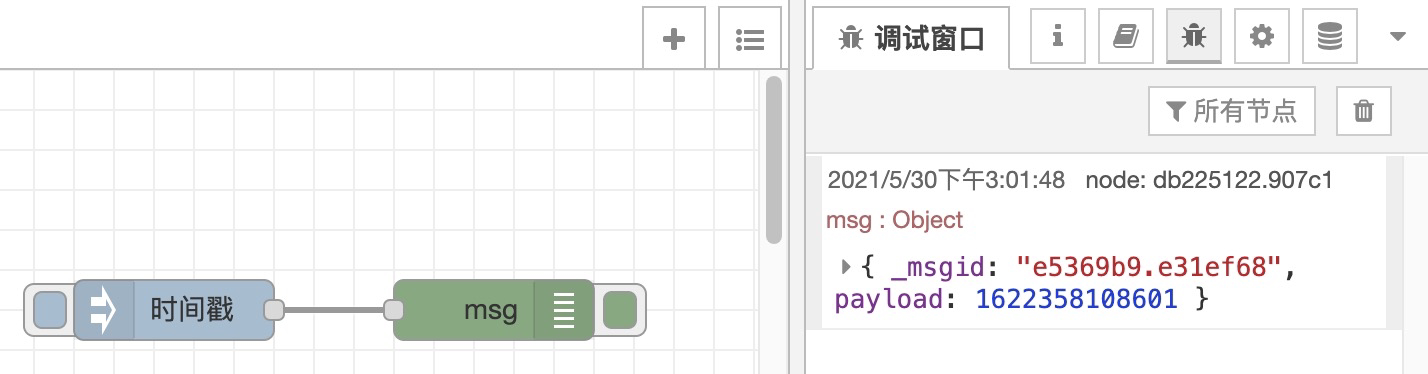
当然如果你把输入连接到 debug,那么原有逻辑就中断了,然而任何输出节点都可以无限制的输出给其它节点,你只要同时把输出连接到 debug 与功能节点就行了:
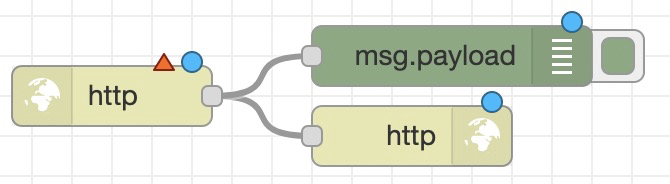
complete

监听某些节点触发完成动作。通过这个节点,我们可以捕获任意节点触发的动作,可以接入 debug 节点打印日志,或者 function 节点处理一下逻辑。
可以监听全部节点,也可以用可视化方式选择要监听哪些节点:
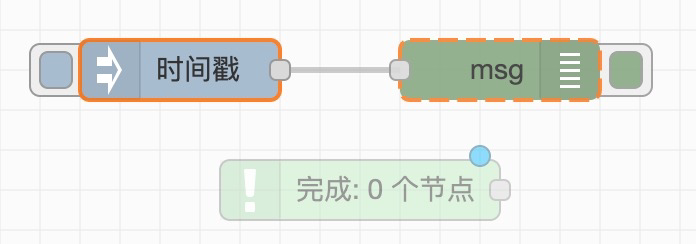
catch

错误捕获节点,当任何或指定节点触发错误时输出,输出的格式为:
1 | |
其实每个节点都有固定输出格式,这些固定格式限制了开发灵活度,但熟练掌握后可以大大提升开发效率,因为所有同类型节点格式都是一样的,这是逻辑编排带来规则约束的好处。
status
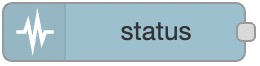
监听节点状态变化。
link in

只能连接 link out。link in、link out 就像一个传送门,用来整理逻辑编排节点,使之看上去易于维护。
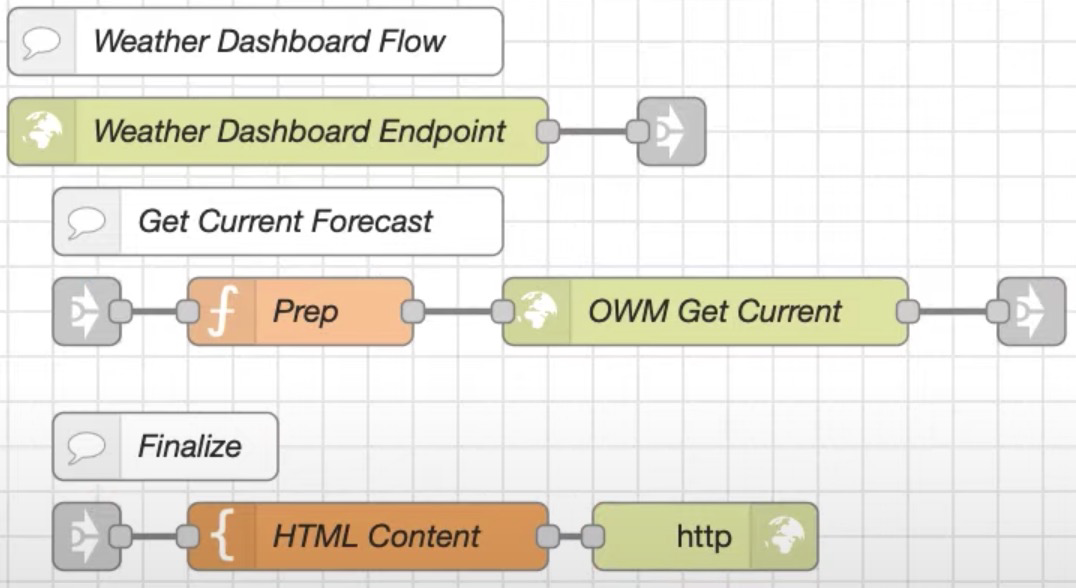
比如下面的例子,在一个天气 http in 服务后,穿插了许多逻辑处理节点,有处理响应 html 内容的 template 节点,也有处理请求查询城市天气的 http request 服务,整体逻辑虽然聚合,但比较杂乱:
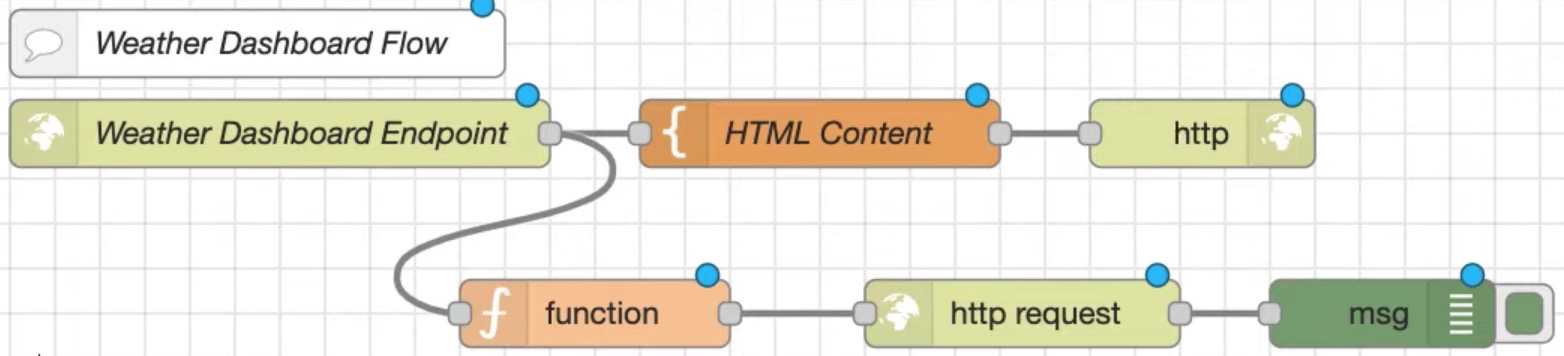
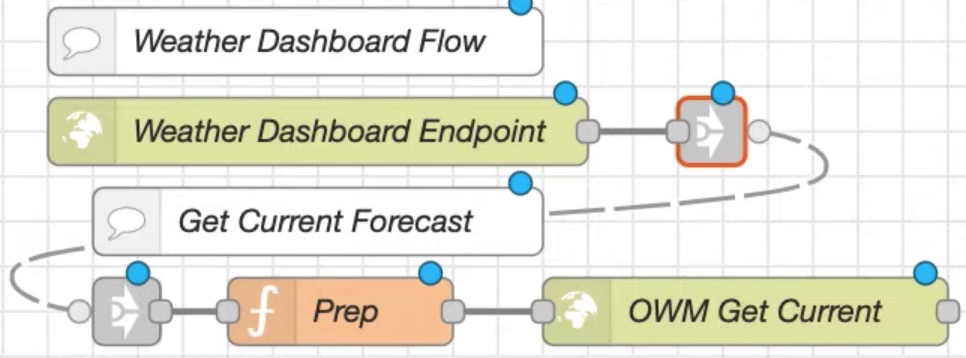
较好的方式是分类,即类似代码开发中的模块化行为,将天气服务导出,其他任何用到的模块直接导入,这个导入动作就是通过 link in 实现的,link out -> link in 只是一个空间位置的变换,传输值是不会变的:
这样模块看起来清晰了许多,如果要知道各个 “传送门” 见连接关系,只要鼠标点击其中一个就可以给出提示,看起来十分方便:
link out
和 link in 成对出现,用来导出输入值,后面对接 link out 可以像传送门一样将值传送过去,在视觉上不会形成连接线。
comment

注释,配合 link 系列使用,可以让逻辑编排 UI 更易于维护。
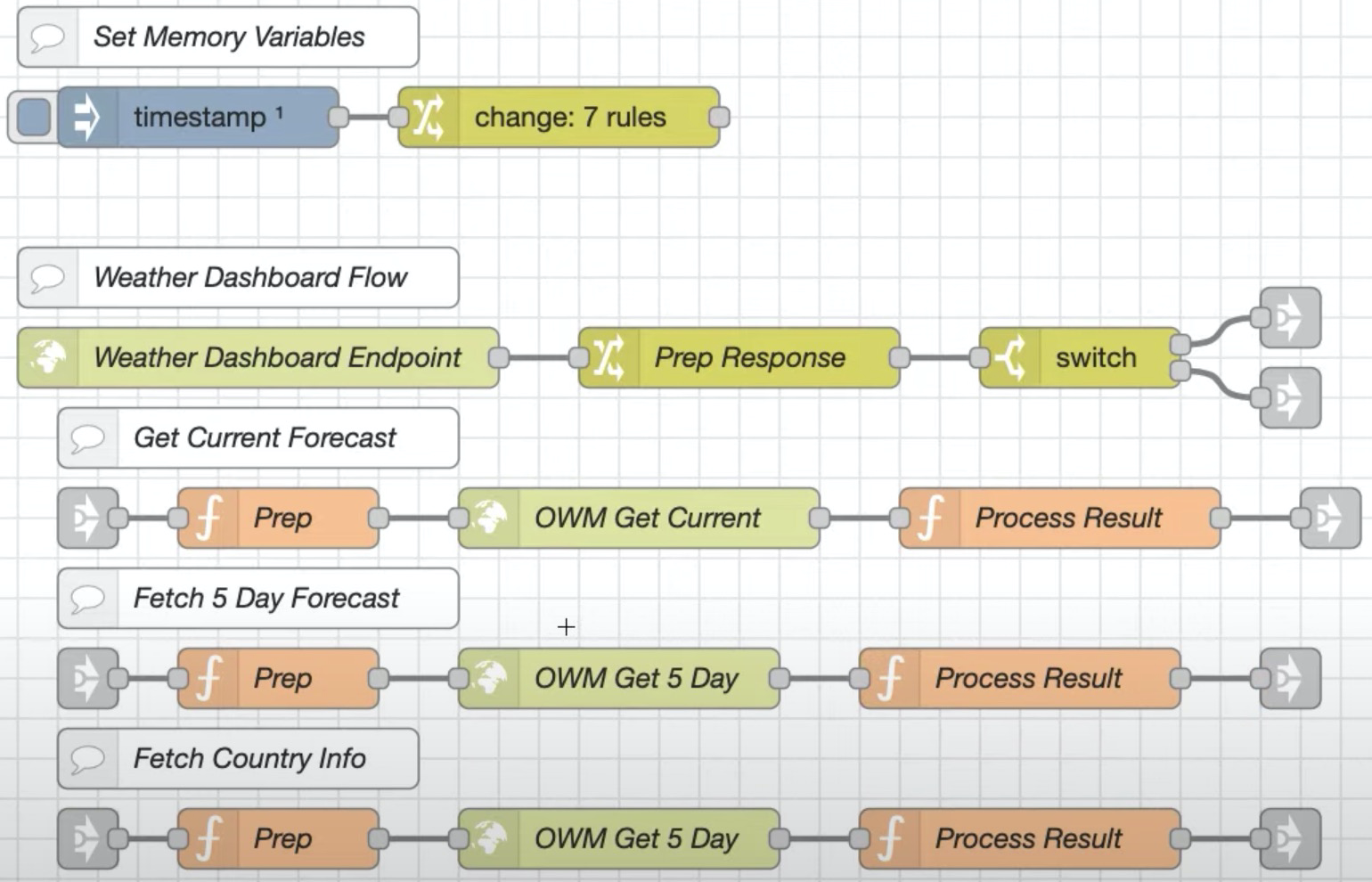
结合原视频的例子,对于天气服务,有创建环境变量逻辑,有查询逻辑,其中查询天气还分为查询当前天气、连续 5 天天气、查询国家信息,我们可以在 UI 上讲每块逻辑分组,并利用 comment 组件标记好注释,方便阅读:
功能
功能型节点,一般用于处理业务逻辑,所以包含了基础的 if else、js 代码、模版处理等等功能模块。
function

最核心的 js 函数模块,你可以用它做任何事:
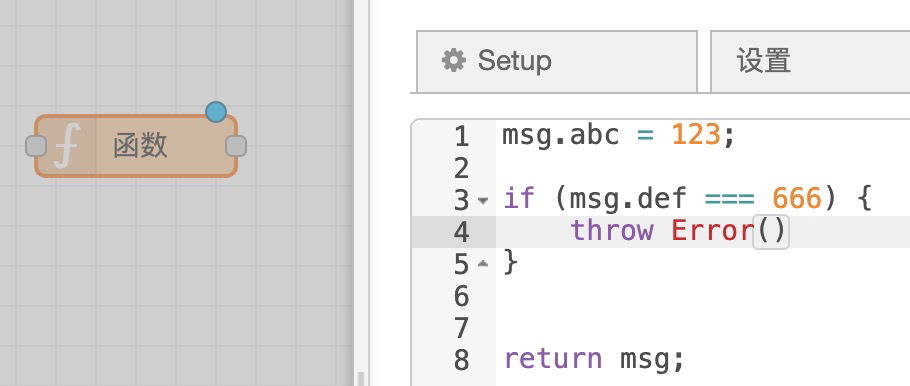
其输入会传导到 msg 对象,可以通过代码修改 msg 对象后再通过输出节点传导出去。
当然也可以访问和修改节点、流程、全局变量,这个在 change 节点里介绍。
switch
对应代码的 switch,只是用起来更加方便,因为我们可以根据不同 case 导出不同的节点:
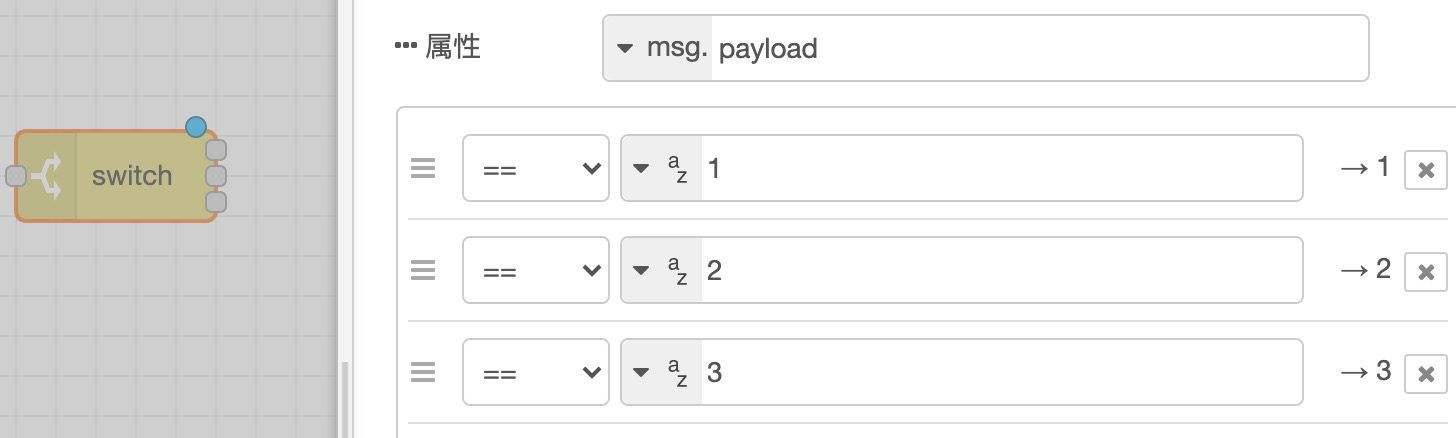
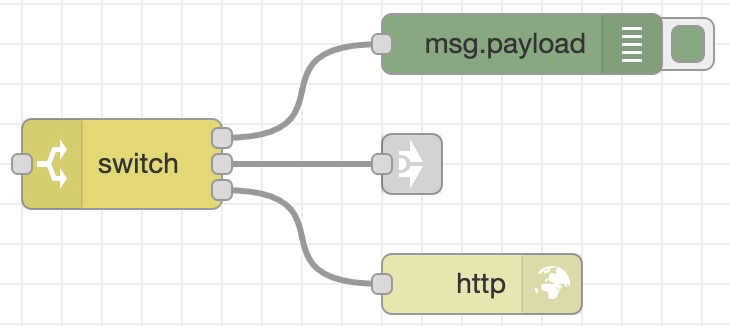
注意看上图,因为有三条分支,所以节点的导出项也变成了三个,我们可以根据不同逻辑走不同的连接:
change
用来改变环境变量。环境变量分为三种,分别是当前节点、流程(画布)、全局(跨应用)。也就是说,变量可以存储在某个节点上,也可以存储在整个画布上,也可以跨画布存储在全局。
访问参数分别为 msg.、flow.、global.,设置这些参数后,就像全局变量一样,任何节点都可以在任何地方使用,比较方便。
比如应用固定了一些 URL 地址,直接把一串字符串写死在某个 http in 节点里并不明智,因为后面的 html 或者其它节点里可能会访问它,一旦你进行修改,影响面会非常广,因此最好将其设置为全局变量,在节点中通过变量方式访问:

其实在控制台,可以看到这三种变量的值:
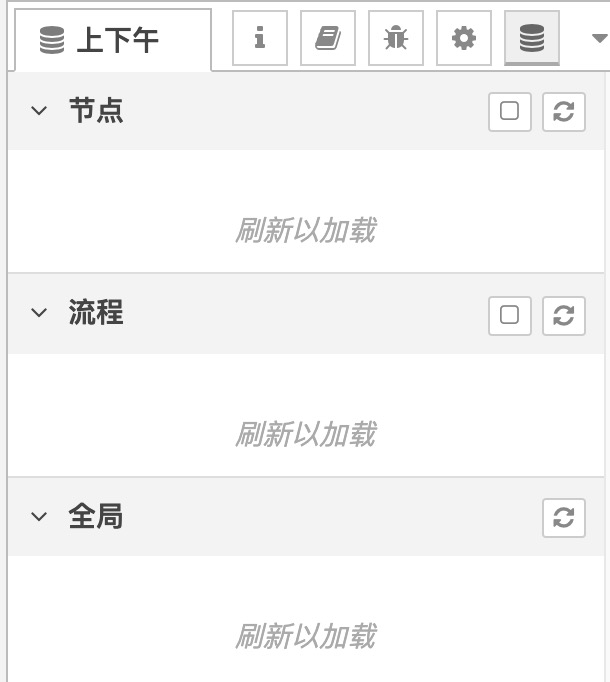
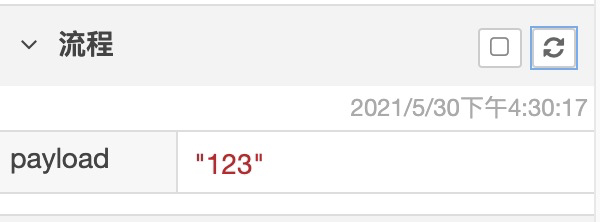
当我们利用 change 节点赋值后,可以通过调试面板查看不同作用域全局变量的值:
range

区间映射,将一个范围的值映射到另一个范围。其实通过 function 模块也能完成,只是因为比较常用所以封装了一个特殊节点。其实用户也可以自己封装节点,具体方式可以参考 官方文档。

上图很容易理解,比如数据分析中归一化就可以用这个节点实现。
template
以模版方式生成字符串或 json。
其实本质上也可以被 function 代替,只是用来写模版的话有高亮,维护起来比较方便。
内置了 mustache 模版语法,通过 {{}} 方式使用变量。
比如我们通过 inject 注入一个变量给 template,并通过 debug 打印,流程是这样的:

其中 inject 是这么配置的:

可以看到,将 msg.name 设置为一个字符串,然后通过 template 访问 name:

delay

延迟发消息,一个快捷的工具,可以放在任何输入与输出中间,比如让上面的例子中,inject 触发后 5s 再打印结果,可以这么配置:

trigger

一个消息触发器,相比 inject,可以更灵活的设置何时重新触发。

从配置可以看出,首先和 inject 一样发送一条消息,然后可以等待,或者等待被重置,或者周期性触发(这样就和 inject 一样),其中 “发送第二条消息到单独的输出” 和 switch 一样会多一个输出口。
然后有重置条件,即 payload 为什么值时重置。
通过这个组件可以看出来,其实每个节点都可以用 function 节点实现,只不过通过定制一个节点,可以用 UI 而非代码的方式配置,使用起来更方便。
exec

执行系统命令,比如 ls 等,这个在系统后台执行而非前端,所以是一个相当危险的节点。
我们可以在配置中写入任何命令:

rbe

异常报告节点(Report by Exception),比如说当输入变化时进行阻塞。
网络
用于创建网络服务,比如 http、socket、tcp、udp 等等,因为其它都不常用,这次仅介绍 http 服务。
http in

创建一个 http 服务,可以是任何接口或者 web 服务。
当你把 Method 设置为 post,连接到 http response 就创建了后端接口;当设置为 get 请求,并连接 template 写上 html 模版,并连接到 http response 就创建了 web 服务。
虽然这种方式创建 web 服务难以使用 react 或 vue 框架,不过自定义节点还是为其创造了可能性,或许真的可以把前端模块化文件定义为节点相互串联。
http response

http 返回,只能对接 http in 的输出,总是与 http in 成对使用。
如果只用了 http in 但没有用 http response,就相当于后端代码里处理了请求,但没有调用类似:
1 | |
来向客户端发送内容。
http request

与 http in 创建一个 http 服务不同,http request 直接发送一个网络请求并将返回值导入到输出节点。
视频中获取天气的例子,就用了 http request 发起请求获取天气信息:
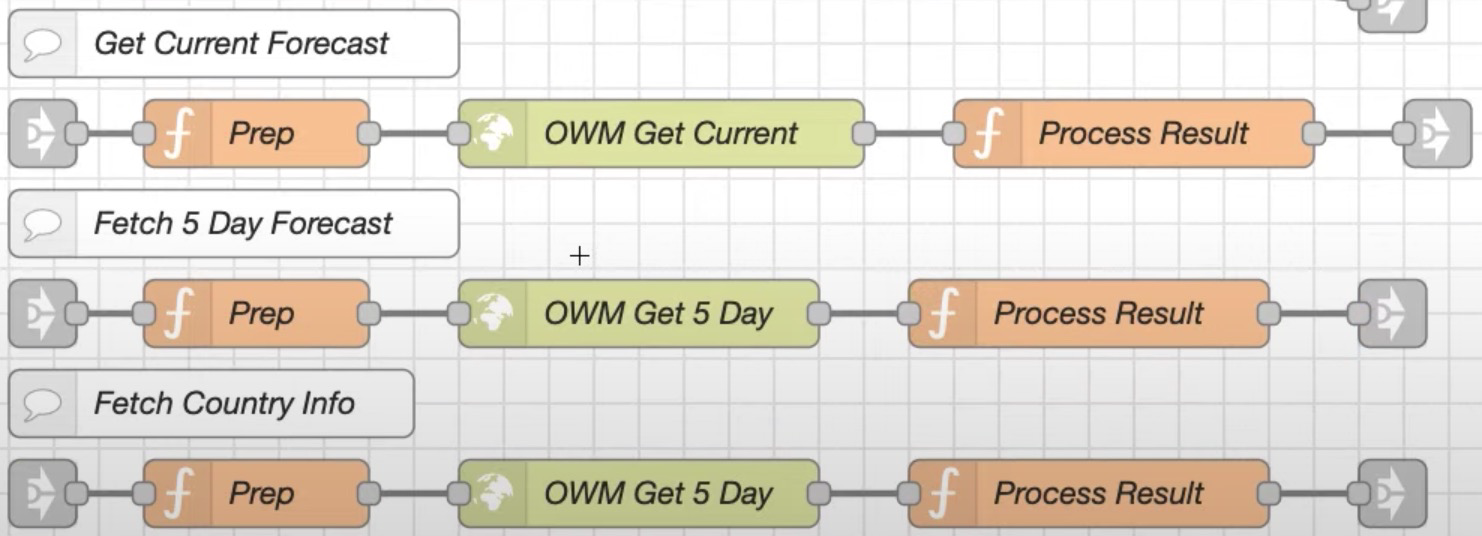
不难看出,发送请求后,又使用了 function 节点处理返回结果。不过在逻辑编排中还是期望少使用 function 节点,因为除非有很好的命名,否则难以看出来节点含义,如果 function 处理内容过多或者 function 区块过多,就失去了逻辑编排的意义。
序列
序列是对数组进行处理的节点。
split
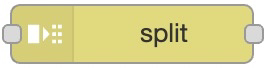
对应代码的 split,将字符串变为数组。
join

对应代码的 join,一般与 split 配合使用,方便处理字符串。
sort

对应代码 sort,只能根据 key 做简单的升序降序处理,对于简单场景比较方便,但对于复杂场景可能还会使用 function 节点代替。
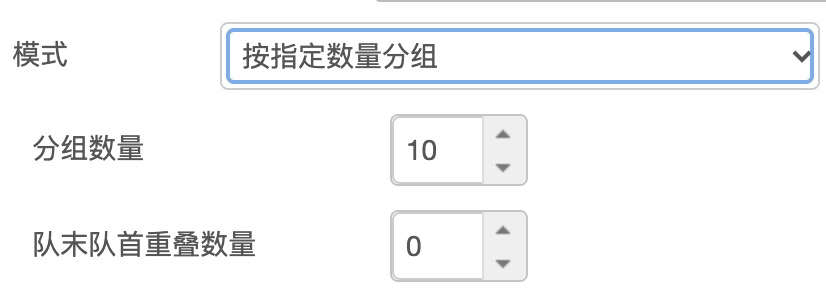
batch

批量接收输入流后,根据数量进行打包后统一输出,等于批量打包,可以按照数量或者时间间隔进行分组:
解析
很容易理解,专门处理上述格式的数据,并按照数据特征输出,比如 csv 数据,可以每行一条消息的方式输出,或者打包为一个大数组以一条消息输出。
当然也可以被 function 节点代替,那么解析方式与输出方式都可以自定义。
存储
持久化存储,一般存储为文件。
file
输出为文件。
file in
以文件作为输入,并将文件结果作为输出。
watch
监听目录或文件的修改。
精读
看了上面 node-red 功能后,相信你对逻辑编排已经有较为体系化的认识了。
逻辑编排的目的是为了让非研发人群也可以快速上手研发工作,因此注定是为 paas 工具服务的,而逻辑编排到底好不好用,取决于节点功能是否完备,以及各节点之间通信是否顺畅,像 node-red 逻辑编排方案,在完备性上做的较为成熟,可以说只要熟练掌握了几个核心节点规则,使用起来还是非常提效的。
逻辑编排也有天然缺点,就是当所有节点都退化为 function 节点后,会存在两个问题:
- 所有节点都是
function节点,即便有说明,但内部实现逻辑非常自由,导致逻辑编排无法起到约束输入输出的作用。 - 退化到代码函数式调用,本质上与写代码无异。逻辑编排之所以提效,很大程度上是我要的业务逻辑刚好与节点功能匹配,以低成本 UI 配置的方式实现效率才高。
然而这也是有解决方法的,如果你的业务无法被现有的逻辑编排节点满足,你可以尝试抽象一下,自己梳理出业务常用的节点,并用合理的配置封装,只要常用业务逻辑可以被封装为逻辑节点,逻辑编排就还有为业务提效的空间。
总结
逻辑编排是一种极端,即用 UI 方式描述通用业务逻辑,降低非专业开发人员的上手门槛。通过对 node-red 的分析可以发现,一个较为完备的逻辑编排系统还是能带来价值的。
然而针对非专业开发人员降本提效还有一种极端,就是完全代码化,但是把代码模块化、函数库、工具链甚至低代码平台建设的非常完备,以至于写代码的效率根本不低,这条路走到极致也不错,因为既然要深入开发系统,同样是投入时间学习,为什么学习写代码就一定比学习拖拽 UI 效率低呢?如果有高度封装的函数与工具辅助,效率不见得比 UI 拖拽来的低。
然而 node-red 在创建前端 UI 的模版上还可以再增强一下,把 template 从节点升级为 UI 搭建画布,逻辑编排仅用来处理逻辑,这样对大型全栈项目的前端开发体验会更好。
如果你想参与讨论,请 点击这里,每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。
关注 前端精读微信公众号

版权声明:自由转载-非商用-非衍生-保持署名(创意共享 3.0 许可证)